[멋사 AI 7기] 멜론 TOP100
![]() Web Scraping
Web Scraping
import pandas as pd
import requests
url = "https://www.melon.com/chart/index.htm"
# 로봇으로 인식하는 것 같음
# pd.read_html(url)
HTTPError: HTTP Error 406: Not Acceptable
사용자 에이전트에서 정해준 규격에 따른 어떠한 콘텐츠도 찾지 못했을 때
로봇으로 인식해 정보를 받지 못하므로 user-agent를 설정 해줘야 함
response = requests.get(url, headers={"user-agent": "Mozilla/5.0"})
response
table = pd.read_html(response.text)
temp = table[0]
temp.head(3)
temp.tail(3)


temp.columns
[‘Unnamed: 0’, ‘순위’, ‘순위등락’, ‘앨범이미지’, ‘곡 상세가기’, ‘곡정보’, ‘앨범’, ‘좋아요’, ‘듣기’,
‘담기’, ‘다운’, ‘뮤비’]
‘Unnamed: 0’ : 선택버튼 무의미한 컬럼
[‘곡 상세가기’, ‘듣기’, ‘담기’, ‘다운’, ‘뮤비’] : 추가 기능
‘순위등락’ : 전처리 해서 사용가능
‘곡정보’ : 제목이랑 가수 구분 필요
‘좋아요’ : 모두 0으로 나오는 데 홈페이지상으론 수치가 나옴, 이유가 뭘까?
‘앨범이미지’ : NaN으로 받아와짐, 추가 처리 필요
[“순위”, “순위등락”, “곡정보”, “앨범”] : 사용
def rank_transform(str_rank):
str_num = str_rank[0]
return int(str_num)
순위 컬럼 수치형 데이터로 변환
ex) 1위 -> 1
df["순위_변환"] = df["순위"].apply(rank_transform)
df[["순위_변환"]].head(3)
![]()
unique_list = df["순위등락"].unique()
unique_list
[‘순위 동일 0’, ‘단계 상승 1’, ‘단계 하락 2’, ‘단계 하락 1’, ‘단계 상승 2’,
‘단계 하락 3’, ‘단계 상승 4’, ‘단계 상승 3’, ‘단계 하락 4’, ‘단계 하락 9’,
‘순위 진입’]
# https://codingspooning.tistory.com/138
# https://kynk94.github.io/devlog/post/re-match-hangul
import re
def regex_hangul(s):
hangul = re.compile('[^ㄱ-ㅣ가-힣+]') # 한글과 띄어쓰기를 제외한 모든 글자
result = hangul.sub('', s) # 한글과 띄어쓰기를 제외한 모든 부분을 제거
return result
슬라이싱을 통해 5글자를 추출해도 되겠지만, 정규표현식을 사용해서 추출해봤음
유니코드 ㄱ : 12593, ㅣ : 12643, 가 : 44032, 힣: 55203
ㄱ-힣으로 지정한다면 12644 ~ 44031의 문자도 포함되므로 ㄱ-ㅣ가-힣으로 지정한다.
for idx, unique in enumerate(unique_list):
unique_list[idx] = regex_hangul(unique)
set(unique_list)
{‘단계상승’, ‘단계하락’, ‘순위동일’, ‘순위진입’}
set로 중복제거
def regex_num(s):
num = re.compile(r'\d+')
result = num.findall(s)[0] # 리스트 형식으로 나와서 0번째 인덱스 값을 가져옴
return int(result)
숫자를 찾아오는 정규표현식
def rank_updown(rank_change):
if regex_hangul(rank_change) == "단계상승":
val = regex_num(rank_change)
elif regex_hangul(rank_change) == "단계하락":
val = -regex_num(rank_change)
elif regex_hangul(rank_change) == "순위동일":
val = 0
else:
val = "new"
return val
단계하락 => 음수, 순위동일 => 0
새롭게 순위에 진입한 경우는 “new”로 변환. 추후 분석 시 수치형 데이터로 변환할 필요가 있어 보임
df["순위등락_변환"] = df["순위등락"].apply(rank_updown)
df[["순위", "순위_변환","순위등락_변환"]].head(20)
![]()
from bs4 import BeautifulSoup as bs
html = bs(response.text)
Pandas로 추출하지 못한 내용들 BeautifulSoup으로 시작
# 제목
# #lst50 > td:nth-child(6) > div > div > div.ellipsis.rank01 > span > a
title = html.select("div.ellipsis.rank01 span a")
title_list = []
for t in title:
title_list.append(t.text)
print(len(title_list))
df["제목"] = title_list
제목을 추출해와서 list로 모은 후 DataFrame 컬럼으로 추가
# 가수
#lst50 > td:nth-child(6) > div > div > div.ellipsis.rank02 > a
#lst50 > td:nth-child(6) > div > div > div.ellipsis.rank02 > span > a
#lst50 > td:nth-child(6) > div > div > div.ellipsis.rank02 > span 단 class="checkEllipsis"
# musician = html.select("div.ellipsis.rank02 a") # 여기로 접근하면 span에 있는 a 도 불러와져서 가수가 2번씩 뽑힘
# musician = html.select("div.ellipsis.rank02 span a") # 가수가 여러명이면 여러개 뽑힌다
musician = html.select("div.ellipsis.rank02 span.checkEllipsis")
musician_list = []
for m in musician:
musician_list.append(m.text)
print(len(musician_list))
df["가수"] = musician_list
가수를 추출해와서 list로 모은 후 DataFrame 컬럼으로 추가
df[["제목", "가수"]].head()
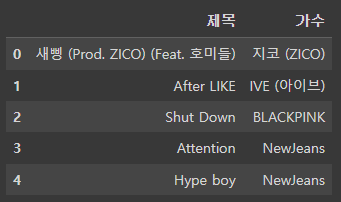
# 앨범 이미지
#lst50 > td:nth-child(4) > div > a > img
# https://cdnimg.melon.co.kr/cm2/album/images/110/45/985/11045985_20220905151107_500.jpg/melon/resize/120/quality/80/optimize
# optimize를 없애야 큰 이미지를 얻을 수 있겠다
image = html.select("div a img")
img_list = []
for img in image[2:]: # 첫 줄 melon img, 둘째줄 불필요
img_list.append(img["src"].split("/melon")[0])
print(len(img_list))
/melon 뒤로 resize optimize를 없애줘야 본 크기의 이미지를 얻어올 수 있다.
df["앨범이미지_변환"] = img_list
df[["앨범이미지_변환"]].head()

#lst50 > td:nth-child(8) > div > button > span.cnt
# 이것도 0으로 뜸, 문제가 뭘까?
html.select("span.cnt")[9]
requests get을 사용해 불러오면 수치가 0으로 나온다.
BeautifulSoup으로 변환해도 마찬가지
# 멜론에서 Javascript를 사용해서 좋아요 수를 실시간으로 불러옴
# BeautifulSoup은 정적 페이지 정보만 가져옴 Selenium 같은 동적 정보 가져오는 툴이 필요
# BeautifulSoup만 사용해서 가져오는 방법이 없을까
# https://sdallman.medium.com/web-scraping-dynamic-content-only-using-beautiful-soup-631496473c0e
# 좋아요 javascript code
# likeAttr = data-song-no
# SUMMCNT가 좋아요 수
html.select("script")[5]
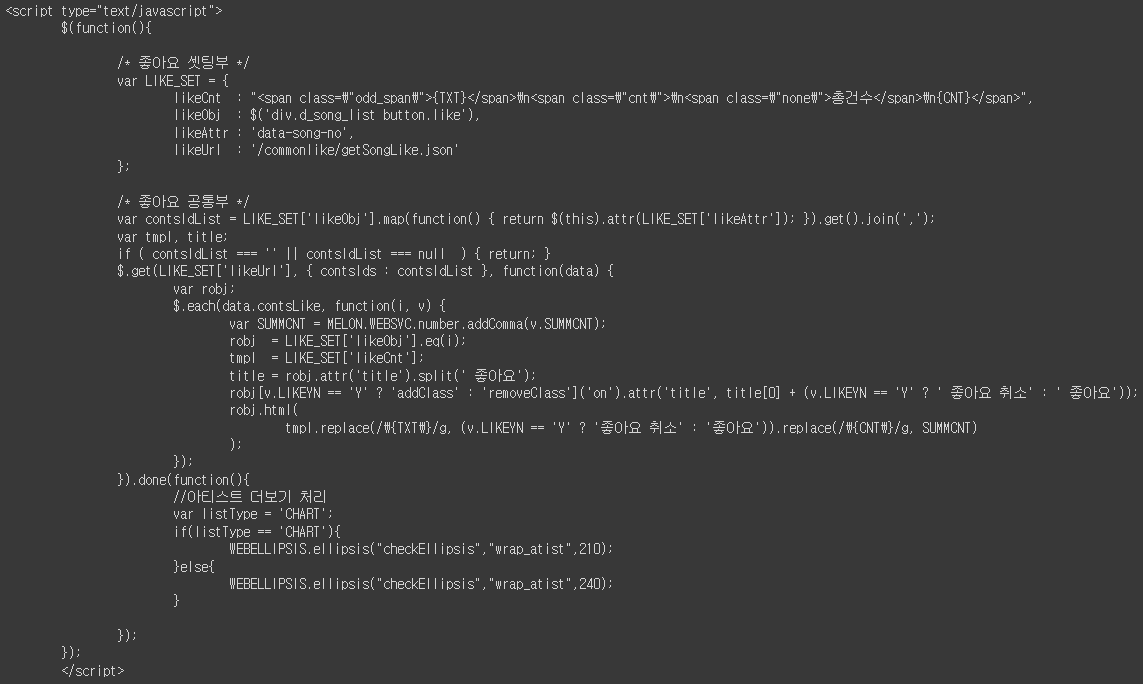
(JavaScript Like Func)
위의 JavaScript Like Func를 보면 좋아요 데이터는 Javascript를 통해 동적으로 불러온다.
Selenium을 사용해 불러와도 되겠지만, 팀장님이 알려주신 위 출처 사이트를 통해 BeautifulSoup으로도 가능하다는 걸 알게 됐다.
#lst50 > td:nth-child(8) > div > button
button = html.select("button.button_etc.like")
data_song_no = []
for b in button:
data_song_no.append(b["data-song-no"])
print(len(data_song_no))
Like Func의 attr인 data-song-no를 추출해와서 리스트에 넣어준다.
# 여러개를 한번에 뽑기 위해서는 "song_no1, song_no2,, song_noN"의 형태로 넣어줘야함
song_no = ", ".join(data_song_no)
cashflow = f"https://www.melon.com/commonlike/getSongLike.json?contsIds={song_no}"
cf = requests.get(cashflow, headers={"user-agent": "Mozilla/5.0"})
cfdata = cf.json()
리스트에 있는 데이터를 콤마 구분자 형식의 문자열로 만들기 위해 join을 사용
df_like = pd.DataFrame(cfdata["contsLike"])
df_like.head()
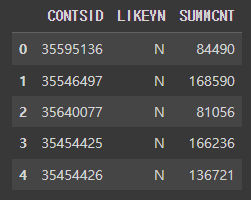
df["좋아요_변환"] = df_like["SUMMCNT"]
필요한 SUMMCNT : 좋아요 수 만 뽑아서 DataFrame 컬럼에 추가한다.
df_last = df[["순위_변환", "순위등락_변환", "앨범이미지_변환", "제목", "가수", "앨범", "좋아요_변환"]]
df_last.head(3)

df_last.columns = ["rank", "rank_change", "img_url", "title", "musician", "album", "like"]
알아보기 쉽게 컬럼명 바꿔준다.
# 이미지 저장
# https://www.delftstack.com/ko/howto/python/download-image-in-python/
# def jpg_load(name, url):
# f = open(name + '.jpg','wb')
# response = requests.get(url)
# f.write(response.content)
# f.close()
# https://stackoverflow.com/questions/16476924/how-to-iterate-over-rows-in-a-dataframe-in-pandas
# for idx, row in df_last.head().iterrows():
# jpg_load(row["title"], row["img_url"])
저장할 이미지의 이름과 URL을 Parameter로 가지는 이미지 저장 함수
지금까지 만든 DataFrame으로 이미지를 저장하고 싶다면 위 코드를 실행하면 된다.
#conts > div.multi_row > div.calendar_prid.mt12 > span.yyyymmdd > span class="year"
#conts > div.multi_row > div.calendar_prid.mt12 > span.hhmm > span class="hour"
today = html.select("span.year")[0].text + "_" + html.select("span.hour")[0].text
file_name = f"top100-{today}.csv"
df_last.to_csv(file_name, index=False)
스크래핑한 URL의 날짜와 시간을 받아와서 만들 csv의 이름 설정
top100-yyyy.mm.dd_hh:mm.csv로 저장
pd.read_csv(file_name)

 출처
출처
- 멜론차트 TOP100https://www.melon.com/chart/index.htm
- 정규표현식 텍스트 전처리
https://codingspooning.tistory.com/138
https://kynk94.github.io/devlog/post/re-match-hangul
- Web scraping dynamic content only using beautiful soup
https://sdallman.medium.com/web-scraping-dynamic-content-only-using-beautiful-soup-631496473c0e
- 이미지 저장
https://www.delftstack.com/ko/howto/python/download-image-in-python/
- DataFrame iterrows
https://stackoverflow.com/questions/16476924/how-to-iterate-over-rows-in-a-dataframe-in-pandas
![]() 포스팅 공지
포스팅 공지
작성한 포스팅은 멋쟁이 사자처럼 AI SCHOOl의 수업 내용입니다.
댓글남기기